データ包絡分析(DEA: Data Envelopment Analysis)は,分析対象の効率性を評価するための手法である.DEAでは,分析対象のことをDMU(Decision Making Unit)と呼ばれ,複数の入力(input)から複数の出力(output)への変換を行うものである.
下の表は,いくつかのDMUの例を示している.
| 店舗 |
店員数,面積 |
売上高,顧客数 |
| 大学 |
教員数,研究費 |
卒業生数,論文数,特許数 |
| 病院 |
医師数,看護師数,ベッド数 |
患者数,手術件数,治癒率 |
1入力1出力
\(n\) 個のDMUがあり,\(\text{DMU}_j\) (\(j=1,2,\ldots,n\)) は1つの入力 \(x_j\) と1つの出力 \(y_j\) を持つとする.そのとき,\(\text{DMU}_j\) の効率性は
\[
\frac{y_j}{x_j}
\]
で評価できる.単位入力あたりの出力を表している.この値が大きいほど,効率的であると評価できる.
用語集
| Data Envelopment Analysis (DEA) |
データ包絡分析 |
| Decision Making Unit (DMU) |
意思決定主体;意思決定単位 |
| Reference Set |
参照集合 |
| Efficient |
効率的 |
| Efficient Frontier |
効率的フロンティア |
練習問題
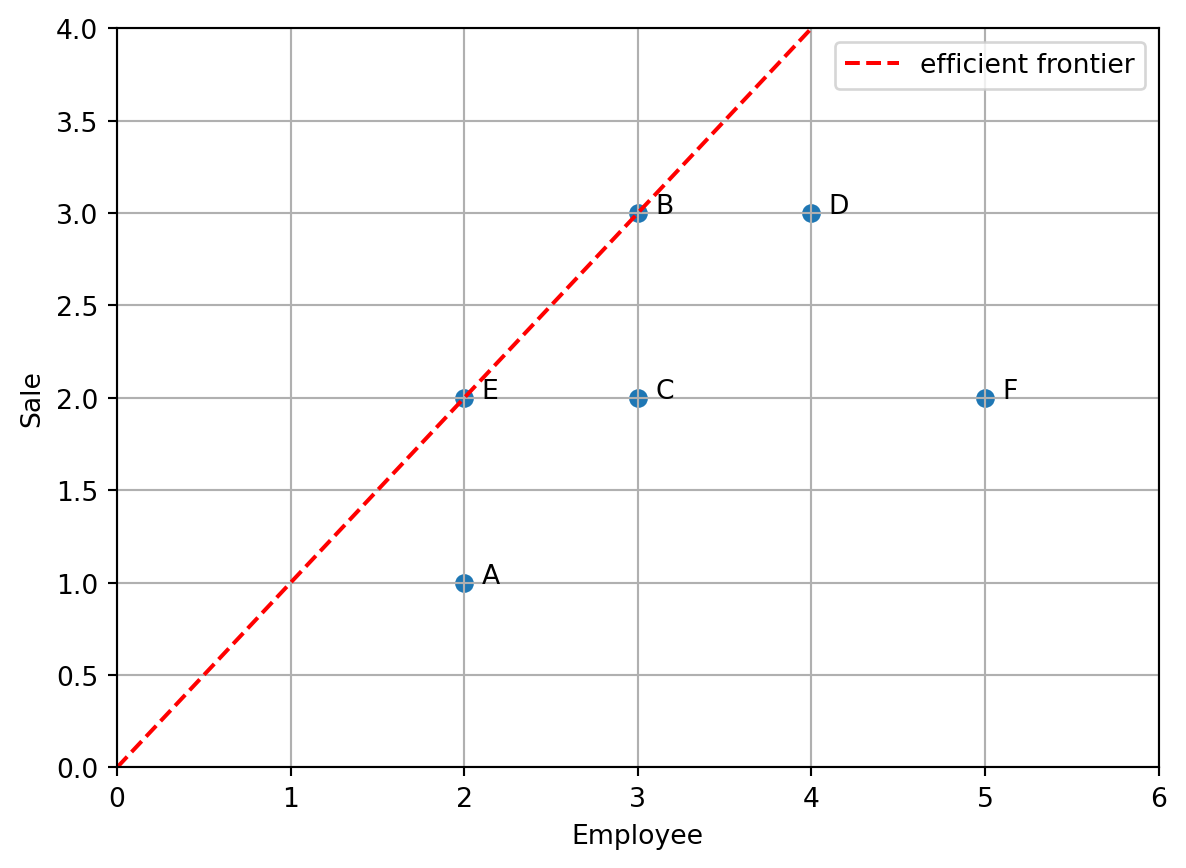
練習 2.1 (1入力1出力) 次の表のような入力と出力が与えられたとき,効率的なDMUを求めよ.効率性を \([0,1]\) の範囲で評価せよ.
| 入力 |
4 |
7 |
8 |
5 |
6 |
| 出力 |
2 |
7 |
9 |
4 |
5 |
解答 2.1.
コード
import pandas as pd
data = {
"DMU": ["A", "B", "C", "D", "E"],
"input": [4, 7, 8, 5, 6],
"output": [2, 7, 9, 4, 5],
}
df = pd.DataFrame(data)
df["efficiency"] = df["output"] / df["input"]
print(df)
DMU input output efficiency
0 A 4 2 0.500000
1 B 7 7 1.000000
2 C 8 9 1.125000
3 D 5 4 0.800000
4 E 6 5 0.833333
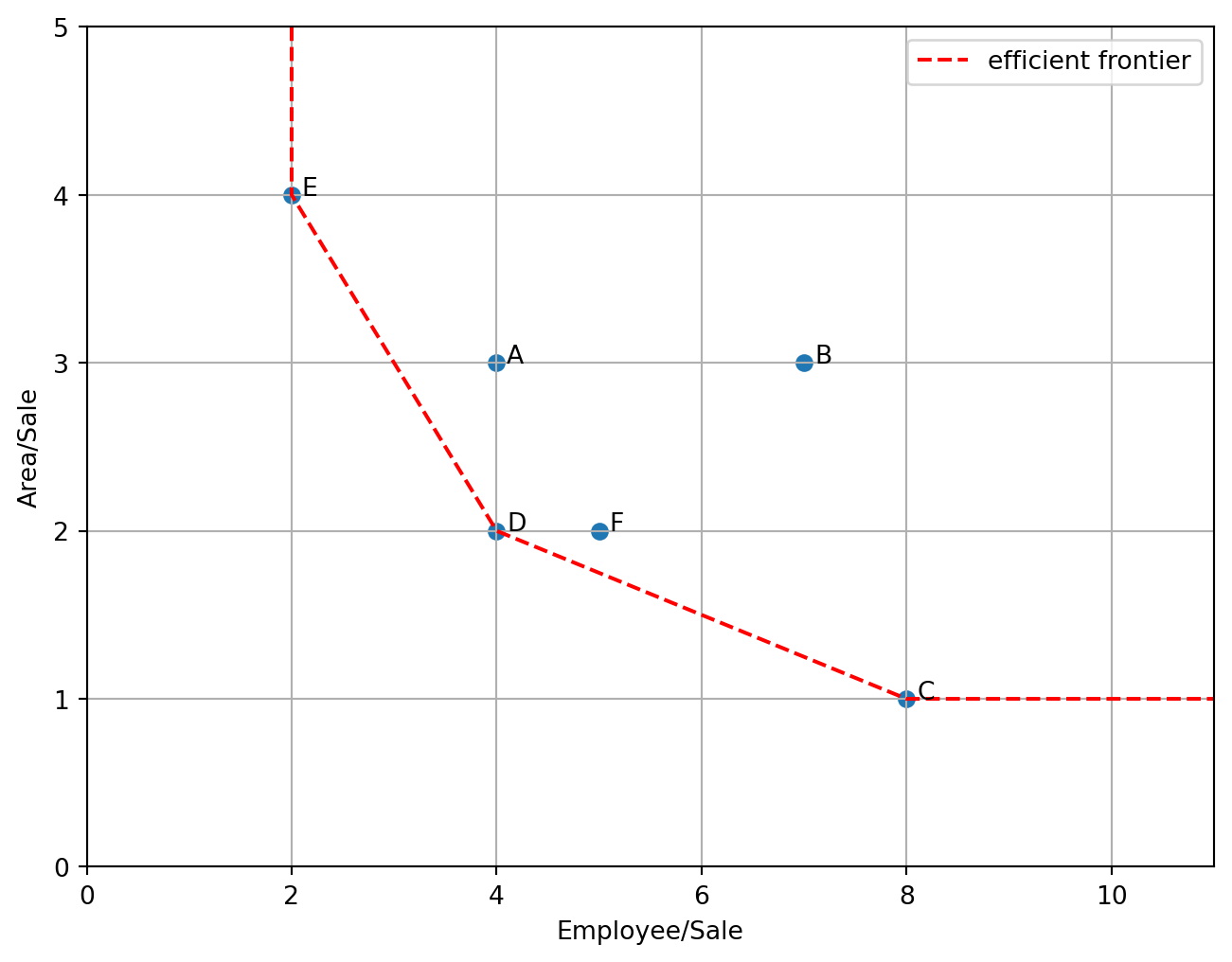
練習 2.2 (2入力1出力) 次の表のような入力と出力が与えられたとき,効率的なDMUを求めよ.
| 入力1 |
6 |
6 |
12 |
4 |
15 |
| 入力2 |
4 |
12 |
9 |
8 |
5 |
| 出力 |
2 |
6 |
3 |
2 |
5 |
解答 2.2. 下の図より,DMU B,Dが効率的であることがわかる.
コード
import pandas as pd
import matplotlib.pyplot as plt
data = {
"DMU": ["A", "B", "C", "D", "E"],
"input1": [6, 6, 12, 4, 15],
"input2": [4, 12, 9, 8, 5],
"output": [2, 6, 3, 2, 5],
}
df = pd.DataFrame(data)
x = df["input1"] / df["output"]
y = df["input2"] / df["output"]
plt.scatter(x, y)
for i in range(len(df)):
plt.text(x[i] + 0.1, y[i], df["DMU"][i])
# 効率的フロンティアの描画 B-E
plt.plot(
[1, 1, 3, 6],
[6, 2, 1, 1],
color="red",
linestyle="--",
label="efficient frontier",
)
plt.xlabel("input1/output")
plt.ylabel("input2/output")
plt.xlim(0, 6)
plt.ylim(0, 6)
plt.grid()
plt.show()