19 機械学習とは
機械学習 (Machine Learning) は,人工知能 (AI) の一分野であり,コンピュータがデータから学習し,予測や意思決定を行う技術である.
19.1 機械学習の種類
機械学習はには,大きく分けて以下の3つの種類がある.
- 教師あり学習 (Supervised Learning)
- 教師なし学習 (Unsupervised Learning)
- 強化学習 (Reinforcement Learning)
19.1.1 教師あり学習
教師あり学習は,入力データとそれに対応する出力データを用いてモデルを学習し,新しい入力データに対して正しい出力を予測することを目的とする.入力データと対応する出力データを「ラベル」とも呼ぶ.
Example 19.1 (文字認識) 教師あり学習の例として,文字認識がある.紙などに書かれた文字を画像として取り込み,テキストデータに変換する技術である. この場合,入力データは文字の画像であり,出力データはその文字に対応するテキストデータである. 訓練データとして,様々な文字の画像とそれに対応するテキストデータのペアを用意する必要がある.
MNISTデータセットは,手書きの数字画像とそれに対応するラベルが含まれており,文字認識の訓練データとして広く利用されている.Tensorflow
出力データの種類に応じて,教師あり学習はさらに回帰と分類に分けられる.出力データが連続値の場合は回帰,離散値の場合は分類である.
Code
# 回帰の例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# データ生成
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# モデル学習
model = LinearRegression()
model.fit(X, y)
# 予測
X_new = np.array([[0], [2]])
y_predict = model.predict(X_new)
# プロット
plt.scatter(X, y)
plt.plot(X_new, y_predict, color="red", linewidth=2)
plt.xlabel("X")
plt.ylabel("y")
plt.show()
# 分類の例 two moons
from sklearn.datasets import make_moons
from sklearn.svm import SVC
# データ生成
X, y = make_moons(n_samples=100, noise=0.1, random_state=0)
# モデル学習
model = SVC(kernel="rbf", gamma="scale")
model.fit(X, y)
# 予測
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors="k")
plt.show()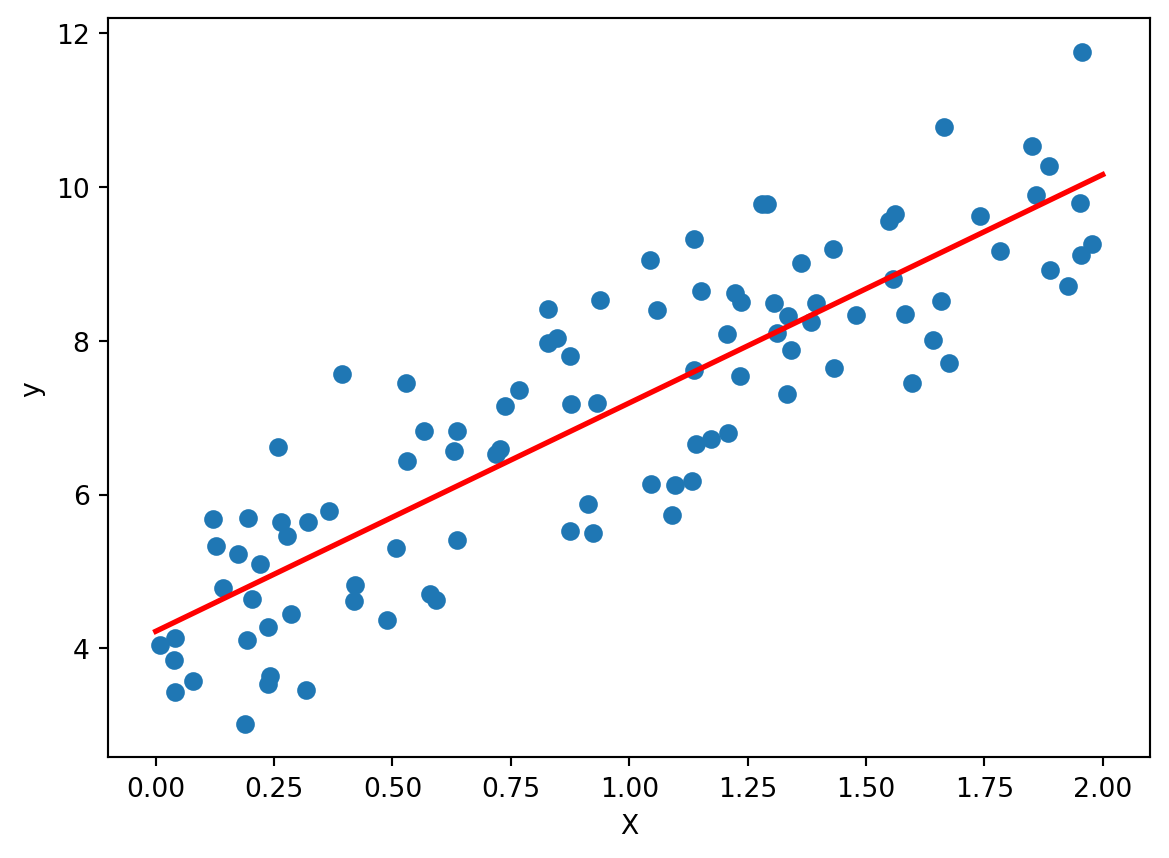
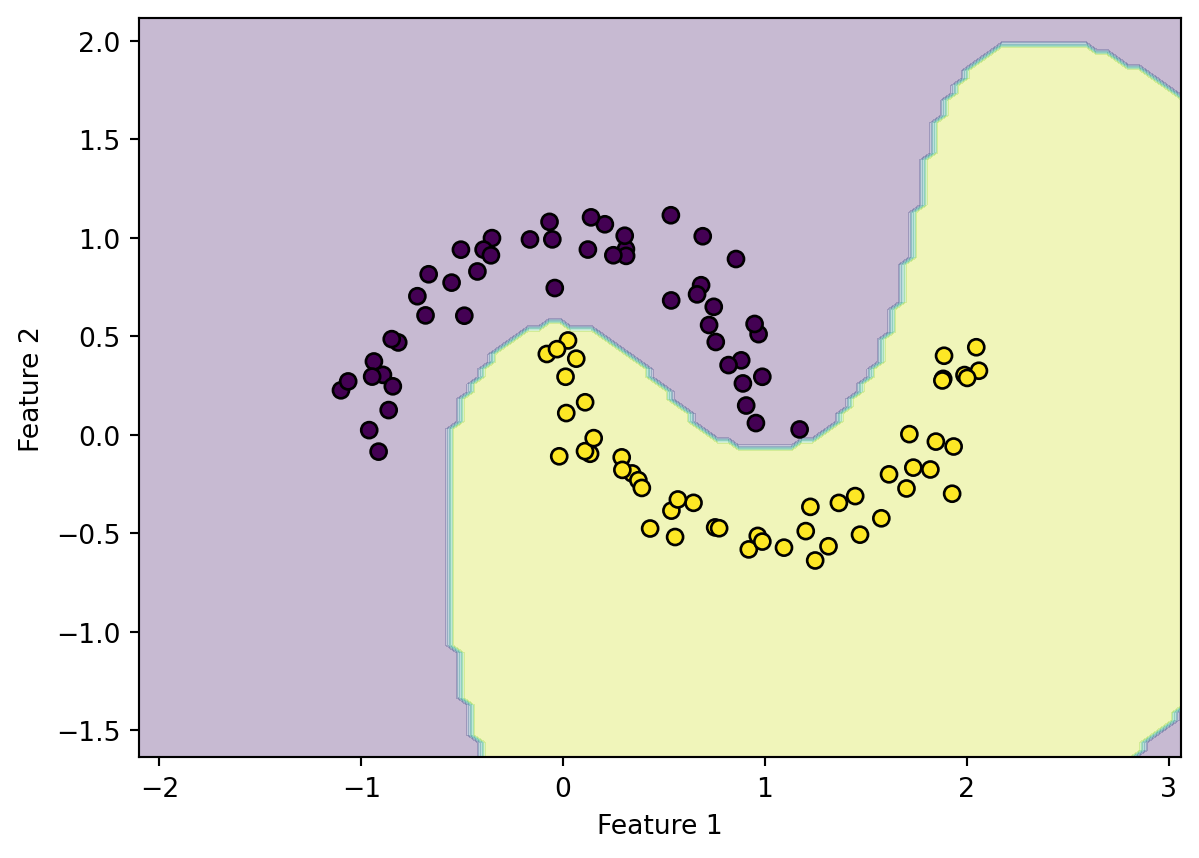
分類の応用例として,スパムメールの検出,画像認識などがある.
回帰の応用例として,株価予測,天気予報などがある.
19.1.2 教師なし学習
教師なし学習は,入力データのみを用いてデータの構造やパターンを見つけ出すことを目的とする.
教師なし学習には様々な手法があるが,代表的なものとしてクラスタリングと次元削減がある.
19.1.2.1 クラスタリング
クラスタリングは,データをいくつかのグループに分ける手法である.同じグループに属するデータは互いに似ており,異なるグループに属するデータは異なる特徴を持つ.
Code
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
# データ生成
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# モデル学習
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
# プロット
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap="viridis")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()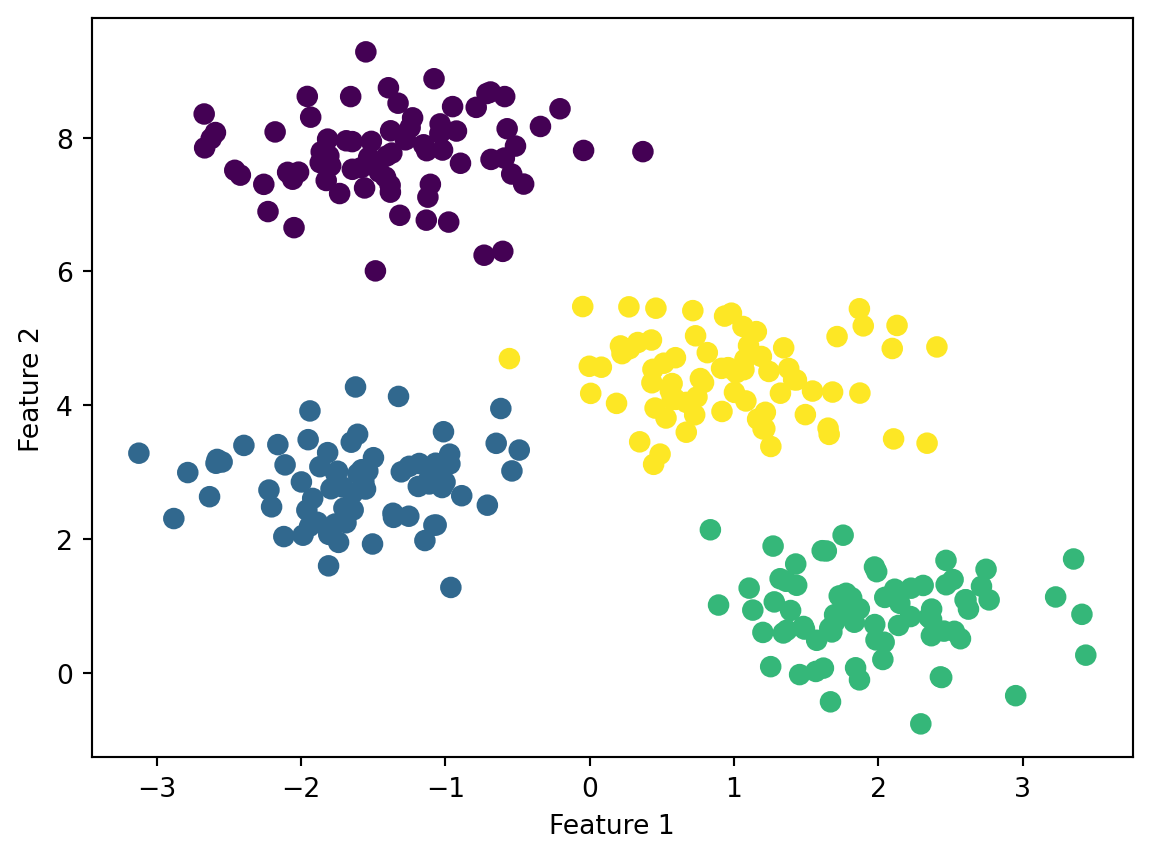
クラスタリングの応用例として,顧客セグメンテーションなどがある.
19.1.3 強化学習
強化学習は,エージェントが環境と相互作用しながら,報酬を最大化する行動を学習する手法である.
強化学習の基本的な要素は以下の通りである.
- エージェント (Agent): 行動を選択する主体
- 環境(Environment): エージェントが相互作用する対象
強化学習の応用例として,ゲームプレイ,ロボット制御などがある.
19.2 研究事例
- 機械学習を用いた選挙不正の検出 (Alvarez 2016)
- 教師あり学習を用いた個人の属性推定 (Doi, Mizuno, and Fujiwara 2021)